Pertanyaan
yang paling sering timbul dalam evaluasi sebuah algoritma clustering adalah seberapa baik solusi clustering jika dibandingkan dengan pengelompokan yang
dilakukan oleh manusian. Himpunan data yang sudah dikelompokan secara manual
ini, menjadi informasi eksternal yang dapat digunakan untuk evaluasi suatu
algoritma clustering. Evaluasi dengan
kriteria eksternal dilakukan dengan membandingkan informasi eksternal ini
dengan hasil solusi algoritma clustering.
Sehingga untuk melakukan evaluasi dengan kriteria ini, diperlukan koleksi uji
yang sudah dikelompokan sebelumnya secara manual.
Informasi eksternal
yang digunakan dalam melakukan validasi berupa solusi cluster L yang sudah dibuat
sebelumnya. Setiap objek dimasukan ke dalam sebuah cluster (pada koleksi uji, biasanya disebut label) Li dimana banyaknya cluster dalam L tidak harus sama dengan banyaknya cluster pada C.
Terdapat
beragam metode evaluasi yang memanfaatkan kriteria eksternal. Umumnya metode
tersebut menggunakan contingency table
seperti pada tabel berikut :

Keterangan :
a = banyaknya
pasangan objek yang berada dalam cluster
C yang sama dan memiliki label L yang
sama (true positive).
b = banyaknya
pasangan objek yang berada dalam cluster
C yang sama dan memiliki label L yang
berbeda (false positive).
c = banyaknya
pasangan objek yang berada dalam cluster
C yang berbeda, namun memiliki label L
yang sama (false negative).
d = banyaknya
pasangan objek yang berada dalam cluster
C yang berbeda, dan memiliki label L
yang sama (true negative).

Beberapa metode yang umum digunakan
adalah sebagai berikut :
Indeks
Overlap :
Evaluasi dilakukan dengan membandingkan cluster
hasil algoritma dengan label yang terdapat pada koleksi uji. Jika diketahui ā =
(a + b)(a + c)
a. Indeks Rand
 |
| Indeks Rand |
b. Indeks Jaccard
 | ||
| Indeks Jaccard |
c. Indeks Fowlkes-Mallows
 | |
| Indeks Fowlkes-Mallows |
d. Statistik Gamma Hubbert (T-statistic)
 |
| T-statistic |
Purity : pengukuran purity dilakukan untuk mengukur seberapa “murni” solusi clustering yang diperoleh. Metode ini dikembangkan dari perhitungan precision yang berasal dari bidang Information Retrieval

Nilai purity dapat diperoleh dengan mencari precision maksimum untuk setiap cluster.
 |
| Nilai Purity |
F-Measure : F-Measure merupakan nilai antara 0 sampai 1 yang mewakili keseluruhan kinerja sistem yang merupakan penggabungan antara precision dan recall yang biasa digunakan pada bidang Information Retrieval. Precision dihitung dari jumlah pengenalan bernilai benar oleh sistem dibagi dengan jumlah keseluruhan pengenalan yang dilakukan oleh sistem, sedangkan recall menyatakan jumlah pengenalan entitas bernama bernilai benar yang dilakukan sistem dibagi dengan jumlah pengenalan entitas bernama, yang seharusnya dikenali oleh system.
 |
| Nilai Recall |
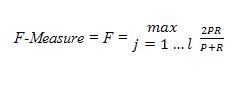 |
| F-Measure |